Cloud data lakes appear like another tech term to denote a database. While it provides a general perspective on cloud-native data lake from a conceptual standpoint, developments on the technology front have brought rapid changes to how data could be leveraged to bring value to businesses. In this context, the cloud data lake is indispensable, as it provides us a clear-cut solution for value extraction and data analysis.
What is a Cloud Data Lake?
A cloud data lake is a cloud-hosted centralized data repository that allows you to store all your structured and unstructured data at any scale, typically using a cloud platform storage service such as AWS S3, Google Cloud Storage, or Azure Data Lake Store.
It helps organizations to store all their structured and unstructured data, without bothering about scale by taking advantage of cloud platform advantages. It allows us to store our data as it is, without problems of initially structuring it and then running various kinds of analytics.
Advantages of Cloud-Native Data Lake
- It is a hassle-free and flexible method to create and maintain databases without keeping any physical hardware.
- It helps to get rid of the tedious process of planning and migration execution. It offers a lot of possibilities despite having core functions, such as data warehouse/database.
Understanding the Data Lake
However, the prospect of data lakes has not yet been realized fully, say tech experts like Van der Drift. He elaborates further that initially when the idea of data lakes received attention, there was no limit to its business potential as to what unstructured data could create. Backed by Artificial Intelligence (AI) and Machine Learning (ML), many firms realized the fact that now they have huge amounts of useful data. They wanted to make better use of the new opportunities and future revenue from it. But, in many instances, it was quite difficult to leverage these
unstructured data from a purely business angle. Also, it could be successful, only if one knows what exactly the user has been looking for. One needs to first make a business case for a cloud-native data lake before creating it.
A data lake helps an organization to improve efficiency and reduce cost as there is no need to invest in hardware or employ developers for maintaining clusters.
Most importantly, the cost to install cloud-native infrastructure will be only 10 per cent of the total cost of a project.
According to the Harvard Business Review (HBR), an organizations’ success very much depends on how it manages its huge amount of data. But data management is not an easy task. Studies have revealed that data breaches are common with over 70 per cent of employees accessing data that they are not supposed to. In addition, analysts spent 80 per cent of their valuable time only to identify and categorize data.
Why We Need a Data Lake?
Any Organization that successfully leverages business value from its data can outperform competitors. According to a survey by Aberdeen, firms which had used a data lake outperformed their rivals by 9 percent in terms of organic growth in revenue. They could manage new kinds of analytics, such as machine learning on log files, social media, etc. It facilitated them to identify new opportunities and utilize them by improving the customer base and productivity and taking informed decisions.
Data Warehouse v/s Data Lake
Each organization requires both a data warehouse and data lake depending on their business requirements. They both serve different purposes.
While data structure and schema are predefined in the case of a data warehouse, they are not defined for a data lake.
Organizations having data warehouses will benefit from data lakes because they have been adding new features to their warehouse to accommodate data lakes and accommodate various query capabilities, advanced capabilities, etc.
How to Use Data Lake on Google Cloud?
A data lake provides organizations the flexibility to store huge amounts of business information in the form of data. Despite this data accumulating into a mammoth size over time, by separating storage and computing, an organization can economically store the entire data.
One can adopt a number of techniques to get insights from data after capturing and storing it.
Challenges in Maintaining an On-Premise Data Lake
Every organization faces some formidable challenges when it comes to maintaining an on-premise data lake. Let us try to understand the main obstacles.
- Data Ingestion: Web crawlers and open data crawlers are two examples of ingestion. Organizations maintain their own data ingestion facilities. As the process requires interactions with external data sources having limited bandwidth, the ingestion should be completed with low latency and a high level of parallelism. So that it will not lead do any extensive analysis of downloaded data.
- Data Cleaning: Very little work has been done on cleaning in the realm of the data lake. Relational and logical data cleaning usually needs exact schema information like integrity constraints. But in the case of in data lakes, data has been stockpiled in schema-less heterogeneous files. The postponing of cleaning to the last stages of data processing causes the proliferation of errors.
- Dataset Discovery: Data discovery is a major issue for data lakes. A few remedial steps include generating and enhancing data catalogs and accelerating search.
Advantages of Moving the Data Lakes to Cloud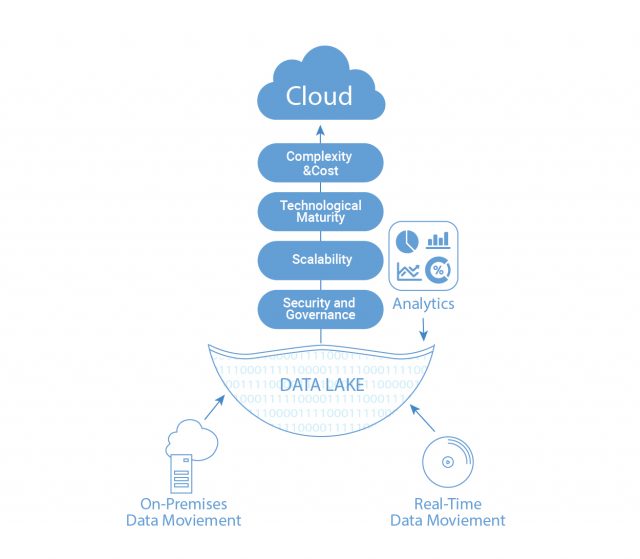
- Complexity and Cost: It is quite tough to manage an on-premise ecosystem since it is too complex and expensive. It demands a good amount of Java skills and command on Hadoop platform, whereas cloud platforms require less technical expertise, and are inexpensive too.
- Technological Maturity: In today’s tech environment, moving complex data from several data sources to an on-premise data lake has become a major challenge to organizations.
- Scalability: One of the main advantages of the cloud infrastructure is its scalability.
- Security and Governance: One of the grey areas of the cloud ecosystem is data privacy. However, these days solutions are available that can take care of most of the security and governance concerns.
Significance of Cloud Storage as Central Data Repository
As we live in a data-driven world, those businesses that efficiently manage their data and generate useful information from them will outperform their competitors. Gemini can help you deploy and maintain a data lake in the cloud and gain insights from it. With our solutions, you can identify opportunities and attract and retain customers in a better manner by making use of the data lake. To know more click here.


